
Cloud Infrastructure Part I: Data + Machine Learning
A look into the data and ML ecosystems today, and where they will go from here

Data Infrastructure & Analytics
Data is at the center of digital transformation efforts worldwide and is becoming a real differentiator for companies of all sizes. Today’s enterprises have launched advanced analytics and data engineering initiatives to better inform and accelerate decision-making. Virtually every company, from SMBs to Fortune 500 businesses, embeds data into its internal workflows and product.
The data market is enormous → IDC expects global big data spend to reach ~$275B this year1. What’s underpinning this spend is a rapid shift to cloud-based storage (i.e. S3, Snowflake, Databricks), with companies taking advantage of unprecedented compute capabilities to run modern analytics on both structured and unstructured data. To show how quickly this market is growing, consider Snowflake. When Snowflake was founded in 2013, the market size for data warehouses was just under $10B. This year, Snowflake estimates their TAM to be ~$90B2.

As data has exploded, companies are increasingly relying on new data infrastructure tooling to support their endeavors. These cloud-based solutions have lowered the technical barriers to managing and handling data. Data engineers and analysts now have developer-like superpowers, greatly advancing data initiatives across the whole organization. It’s no wonder that data engineers are in such high demand. Last year, data engineering job postings had the fastest YoY growth within the tech sector. In 3rd place was data scientists3.

Key Trends Within Data
1) Unbundling of the data stack. It’s fascinating to observe a true open ecosystem develop around cloud data, with a level of interoperability that didn’t exist a decade ago. Storage businesses have unlocked new data use cases “higher in the stack,” allowing vendors within dashboarding, ETL, data observability, real-time, etc. to flourish. Teams are adopting a more modular approach, with hyper-optimized solutions that solve specific painpoints in the flow of data. In my last post, I introduced some of the key early stage startups that make up this open ecosystem. (Btw, I adjusted the categorization for the Data Infrastructure category thanks to some feedback from readers.)

2) Batch → streaming. While batch processing constitutes the majority of data workloads today, we are seeing an increasing proportion of net-new analytical workloads move to real-time and streaming. Hospitals make use of real-time data to determine the number of open beds available to patients. Exchanges like Nasdaq and Binance need real-time data to fill billions of dollars worth of trades each day. Uber and Lyft require real-time data to identify a driver’s location and ETA for ride-hailing users. Streaming data use cases are legion.
3) Empowering data scientists. As the core infrastructure for data systems improves, data scientists have more offerings at their disposal to drive meaningful analyses and derive powerful insights from underlying data. Startups like Anyscale and Coiled are empowering data scientists to run large-scale experiments and build sophisticated models with ease.
4) Emergence of the Lakehouse. A by-product of the war between Snowflake and Databricks is the lakehouse, a new architecture that combines the best elements of data lakes and data warehouses. In the quest to be the central storage layer for data, Snowflake will support unstructured data formats while Databricks is bringing warehousing capabilities to its data lake. The end result is more flexibility for data practitioners.
The Data Budget
Data budgets have meaningfully increased in the past couple of years. I surveyed 60 data leaders in our network within organizations of 500+ FTEs, and nearly ~50% of the enterprises have a data-specific budget greater than $1M. It’s amazing to see some data leaders in charge of $10M+ budgets. Looking ahead, data budgets will continue to expand, with ~25% of enterprises at least doubling their data spend in the next 10 years.

When looking at where these dollars are being spent, I wanted to take a quantitative approach to measuring the priority of each subcategory relative to each other. I asked our data leaders to rank order solutions by total dollars spent. I gave each respondent an imaginary budget of $2M to go spend on the various data categories listed in the market map above. I asked everyone to this now, and for the near future (5-10 years).
Of course, there are some flaws with this survey, i.e. why would you need to spend significant amounts of money on both a data warehouse and data lake? Another assumption is that there will not be some disruptive category that emerges in the coming years. But, the overall data reveals some interesting insights around relative spend today and how budget holders are thinking of data spend in the future.
It’s important to note that teams will use multiple of these vendors as each is an important element within a broader data strategy. But not all categories are created equal, and spend is not distributed evenly.
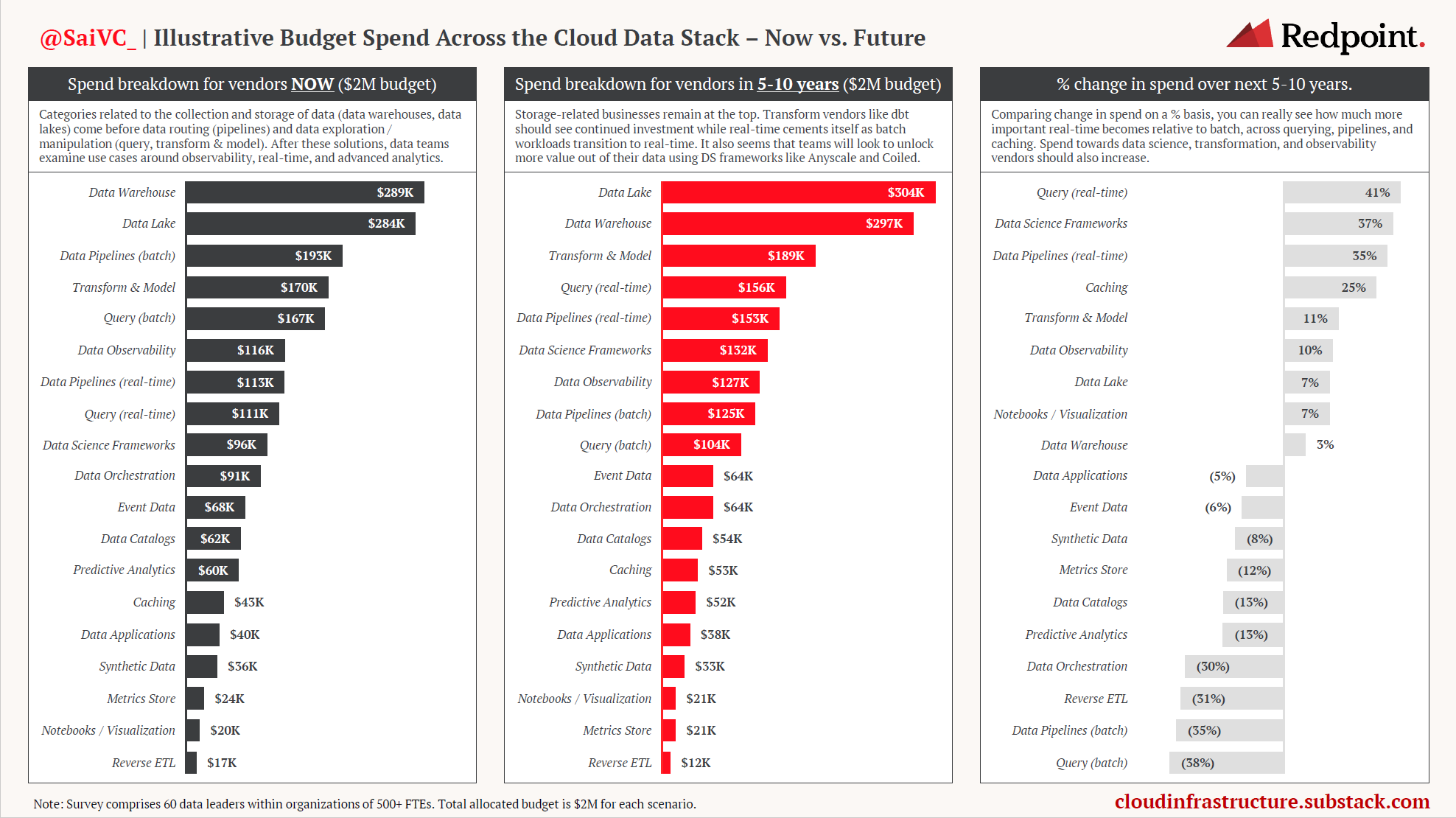
It’s interesting to note that for the most part, data teams follow Monica Rogati’s “Data Hierarchy of Needs.” Categories related to the collection and storage of data (data warehouses, data lakes) come before data routing (pipelines), and data exploration / manipulation (query, transform & model). After these solutions, data teams prioritize use cases around observability, real-time, and advanced analytics.
Where is Data Going?
Storage-related businesses remain at the top. We’re excited to track the innovation happening within this layer. Keep an eye out for companies optimizing the data lake experience like Onehouse and Tabular, which will become more important as overall data lake spend increases. Data transformation vendors like dbt should see continued investment.
It’s clear that real-time related solutions become very important. Real-time querying, streaming pipelines, and database optimization solutions (i.e. caching) will be one of the fastest growing segments in the next few years.
In addition, enterprises will increasingly use vendors like Anyscale and Coiled to expand their data science initiatives. Finally, data observability vendors like Monte Carlo will become more popular as teams aim to limit data downtime.
Machine Learning
The machine learning ecosystem is hitting an inflection point and creating unprecedented value felt by every industry. Advances in natural language processing (NLP) and computer vision (CV) are redefining how we think about deriving value from data. The use cases are myriad and continue to grow. From recommendation engines, embedded search, fraud detection, chatbots, cybersecurity, etc., machine learning is critical for software applications. And spend for ML tools is accelerating → the Enterprise AI market is expected to reach $50B+ in spend by 20274.

What’s unique within the machine learning ecosystem is the incredible contribution by research labs like Microsoft, Google, and Amazon into the field. These technology behemoths have introduced new models and frameworks, and much of the recent progress within this category can be attributed to them. OpenAI, a prominent AI research and deployment laboratory, introduced the powerful GPT-3 language model last year and open-sourced it so that it’s universally available to developers. These language models are akin to AWS servers to build and scale machine learning embedded applications. Companies like Copy.ai and Jasper.ai heavily rely on GPT language models to sell their services.
Key Trends Within ML
1) ML is following the data playbook. Although the machine learning ecosystem isn’t as mature as the data market, similar solutions around pre-processing, data quality, scalability, observability, real-time, etc., are emerging for machine learning practitioners. It’s important to note that there isn’t the required level of interoperability yet within the new machine learning stack, and that stitching together these solutions is challenging. But as with data, we expect machine learning solutions to quickly mature and create a similar open and integrated ecosystem. Below are some exciting ML vendors that I highlighted in my last post.

2) Convergence of software development + machine learning. Machine learning engineers are highly sought-after, and hiring is usually the bottleneck for ML teams. Through MOOCs and online learning, software engineers can become capable machine learning engineers fairly quickly, contributing to ML endeavors within organizations and wear multiple hats within development.
3) Adoption of Deep Learning Use Cases. Deep Learning, a subset of machine learning that uses neural networks inspired by the human brain to “learn” large amounts of data, has been historically confined to research labs with limited enterprise adoption. The limiting factors have been a lack of structured labeled data, appropriate modeling frameworks, and adequate compute resources. Recently, startups like Lambda Labs are enabling enterprise use cases around deep learning.
3) ML-specific budgets. Larger enterprises are carving out machine-learning specific budgets that are separate from data ones. The largest companies usually have a “Head of Machine Learning” with a dedicated junior team and separate budget allocated for ML solutions.
The Machine Learning Budget
While machine learning budgets are smaller than data ones, machine learning is the fastest growing budget within cloud infrastructure. We surveyed 60 ML leaders in our network within organizations of 500+ FTEs, and over 50% expect to double their budget in the next 5 years. ~25% expect to triple their budget.

How are machine learning teams spending their money today? Below is the same survey related to ranked spend, but asked to ML and AI practitioners. A slight difference with this survey was that the total budget for ML solutions was reduced to $1M.

Machine learning frameworks like Cohere and Hugging Face are top-of-mind as they allow ML developers to pick and choose from pre-built models. Hugging Face in particular is one of the fastest growing open-source platforms we’ve witnessed, surpassing repositories managed by companies like Databricks, dbt, and Grafana. Next, we have a category coined “MLaaS,” startups that help turn raw models and data into real-life use cases and machine learning applications. Following that, we have companies that deploy ML models at scale (OctoML) and label your training data (Heartex, Labelbox, Scale.ai).

Where is Machine Learning Going?
When looking out to the future, machine learning frameworks and MLaaS vendors remain at the top.
It will be exciting to see how ML frameworks like Cohere and Hugging Face develop their GTM strategy and scale. Whereas Hugging Face is an open-source repository of models, Cohere extends their close-sourced models through an API available to developers. Both have recent unicorn valuations.
Moving forward, it’s clear that core ML infrastructure like workflow orchestrators (Union.ai) and backends (i.e. Pinecone.io which implements vector embeddings for your unstructured ML data) become critical. Further, model evaluation tools like Comet and Weights & Biases will be the third fastest growing segment as they help teams build better models faster with experiment tracking, dataset versioning, and model management capabilities. Finally, similar to data observability startups like Bigeye and Monte Carlo, ML observability vendors such as Arize and Arthur.ai become more important as they allow companies to measure and optimize model performance in production systems.
Join Our Data + ML Advisory Group
At Redpoint, we have an awesome advisory group of data and ML practitioners at companies like DoorDash, Gojek, Intuit, Lyft, Netflix, Stripe, Twilio, etc. We host seminars, happy hours, and virtual events throughout the year. If you are a data or ML leader and would like to discuss new trends, up-and-coming startups, and in general geek out with other like-minded folks, please drop my colleague Chase Holmes or me a note. We would love to have you!
IDC (2021)
Snowflake 2021 Investor Day Presentation
DICE Tech Job Report (2020)
Gartner (2021)
Who are these data leaders you surveyed? If they work at the companies you are investing in, then that is a biased sample. The 5-10 year time-horizon is interesting, but as the title said it is "illustrative". To what extent was it based on survey data, and to what extent was it based on subjective assessments?
Zing Data - data viz and collaboration